十亿生物序列毫秒检索:ERAST技术架构与AI融合实践深度解析
2019年,当我第一次在服务器上跑BLAST处理人类蛋白质组数据时,等待了整整三天。那个夜晚,我盯着进度条思考:生命科学的计算瓶颈,是否真的无解?
困局:传统序列搜索的时代局限
BLAST诞生于1990年代,其设计哲学建立在序列局部比对之上。在小规模数据库时代,这种方法足够有效。然而,2020年后,UniProt数据库膨胀至2亿+蛋白质序列,传统工具在十亿级数据面前的计算代价已不可接受。更致命的是,BLAST依赖heuristics加速,必然牺牲精度——寻找进化关系遥远的“远亲”时,假阴性率急剧攀升。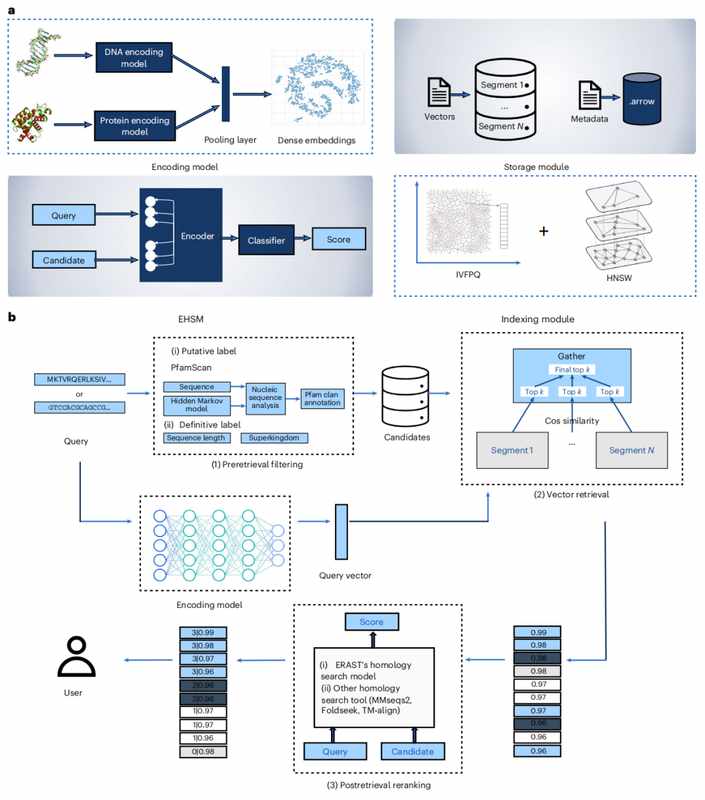
破局:ERAST的技术架构设计
腾讯AI生命科学实验室与浙大的联合团队,选择了截然不同的技术路径。
第一层:序列向量化。团队采用ESM-2蛋白质语言模型与MAMBADNA模型,将生物序列映射为高维向量。每个向量如同分子的“数学指纹”,蕴含序列的结构与功能信息。10亿+蛋白质向量与3000万+核酸向量构建起全球最大生物向量数据库。
第二层:三级检索流水线。预检索阶段利用元数据(序列长度、家族标签)快速过滤;向量检索阶段并行计算余弦相似度,毫秒级完成候选集筛选;后检索阶段引入EHSM评分模型,对候选序列二次打分,尤其擅长识别低相似度远亲。
性能验证:数据说话
SCOPe40测试集结果极具说服力。相比Foldseek,ERAST提速50倍;相比TM-align,提速5万倍;10万碱基对DNA序列检索比BLASTn快60倍。精度方面,Top-1命中精度显著优于TM-Vec、DHR、PLMSearch等主流深度学习方法。
应用拓展:从搜索到功能发现
ERAST不止于检索。团队对UniRef90进行全局聚类分析,发现94%的功能未知蛋白质簇可通过聚类网络与已知功能蛋白质连接。这意味着ERAST能够系统性照亮“蛋白质暗物质”,为功能注释提供全新范式。
工具落地:开源与产业化
该工具已开源(GitHub:TencentAILabHealthcare/ERAST),在线服务已上线(ai4s.tencent.com/erast)。对生物信息学从业者而言,这意味着从耗时的计算等待中解放,更专注于科学发现本身。新药靶点发现、病原体追踪、酶工程设计等研究领域将直接受益。